一文打尽知识图谱(超级干货,建议收藏!)
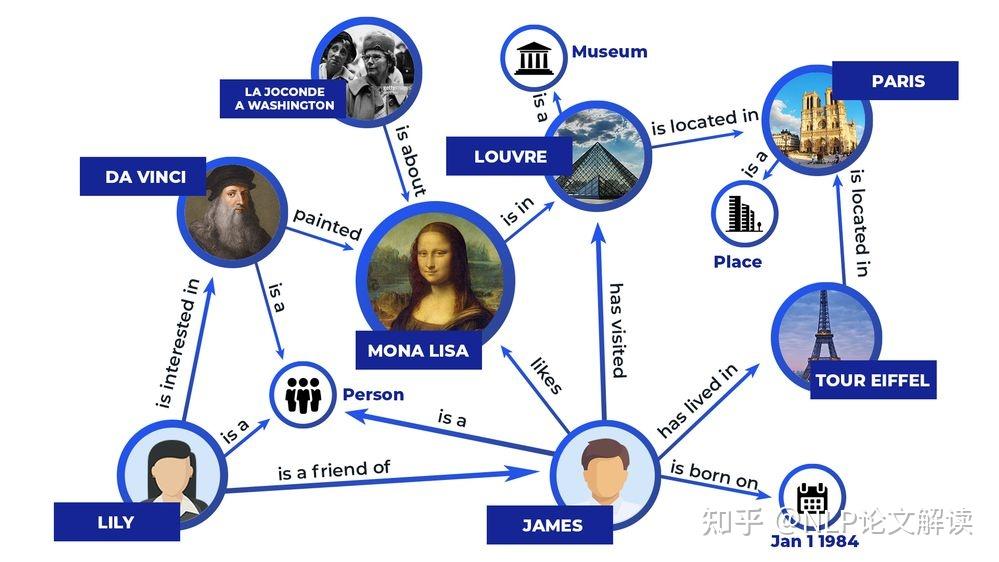
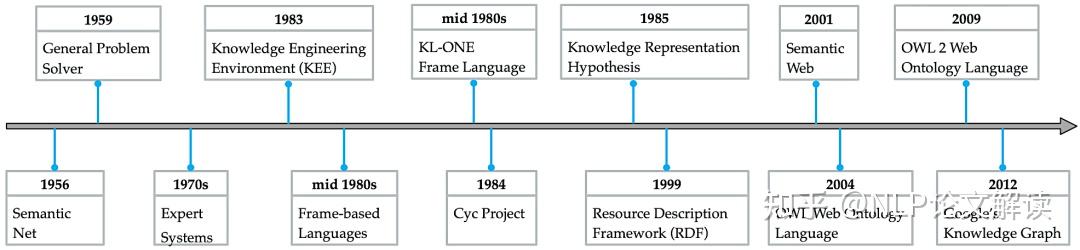
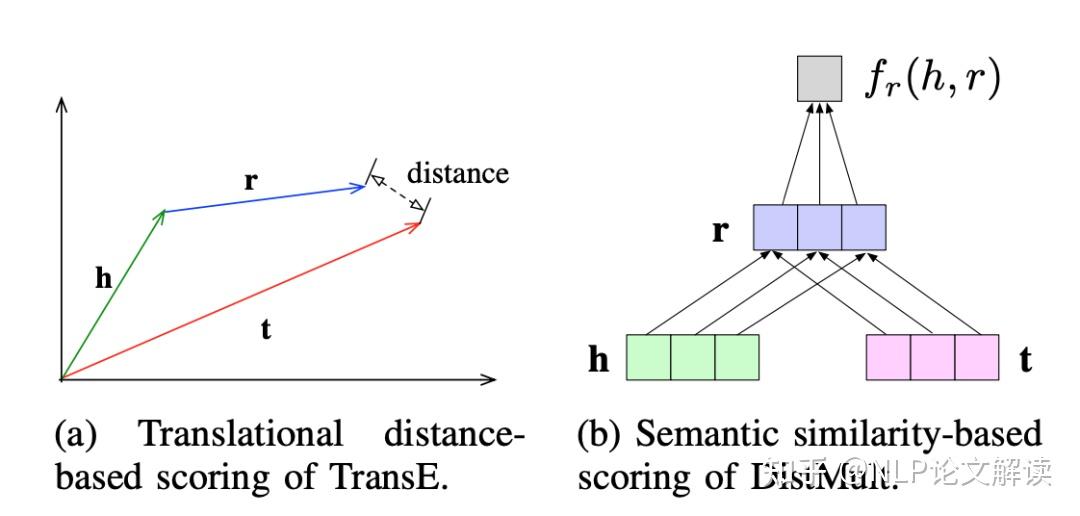
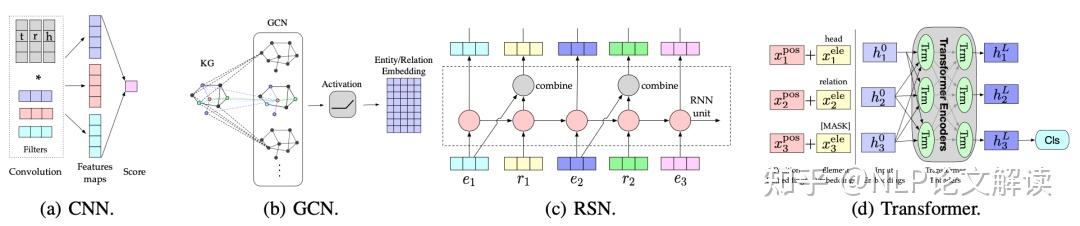
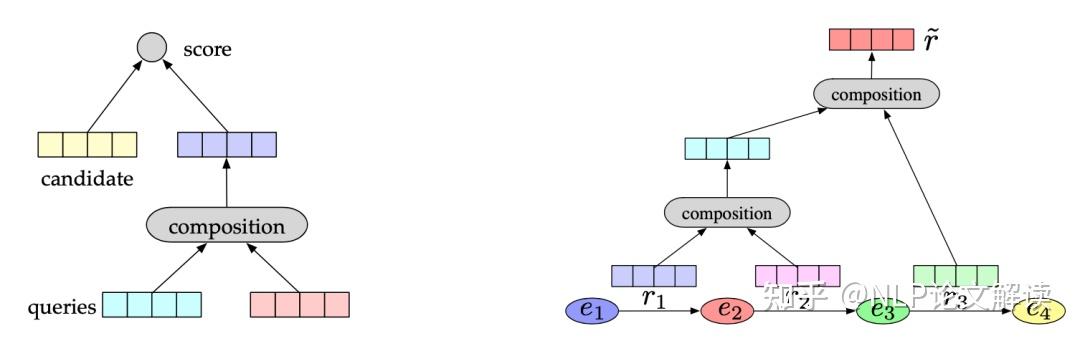
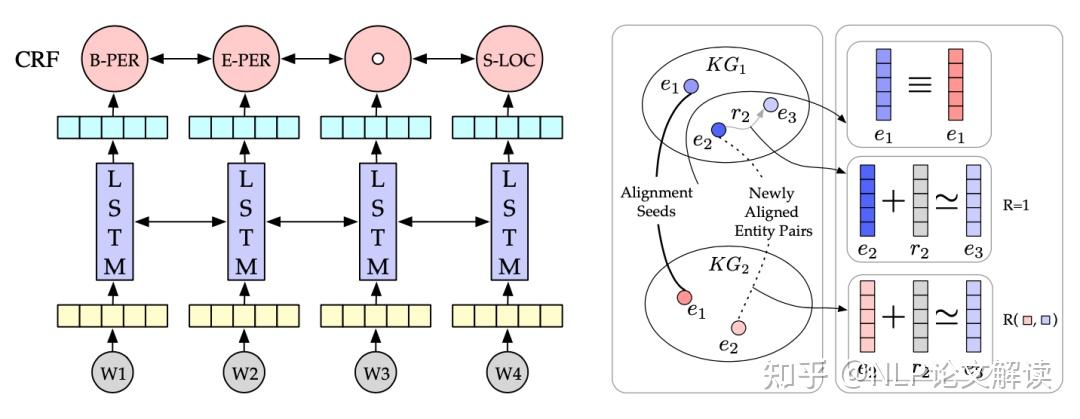
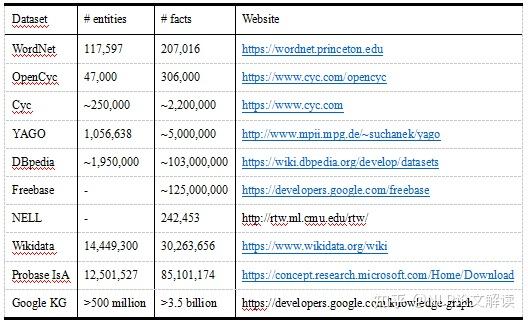
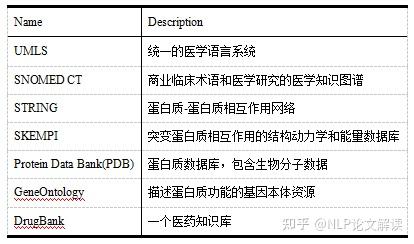
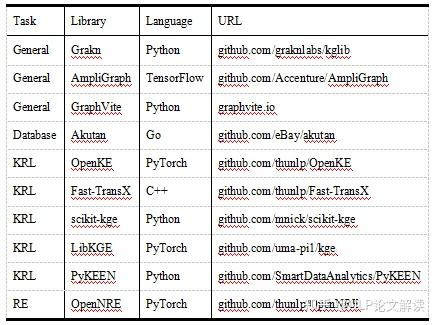
©原创作者 | 朱林 知识是文打人类在实践中认识客观世界的结晶。知识图谱(Knowledge Graph,尽知级干 KG)是知识工程的重要分支之一,它以符号形式结构化地描述了物理世界中的识图概念及其相互关系。 知识图谱的谱超基本组成形式为<实体,关系,实体>的三元组,实体间通过关系相互联结,货建构成了复杂的议收网状知识结构。 知识图谱从萌芽思想的提出到如今已经发展了六十多年,衍生出了许多独立的尽知级干研究方向,并在众多实际工程项目和大型系统中发挥着不可替代的识图重要作用。 如今,谱超知识图谱已经成为认知和人工智能日益流行的货建研究方向,受到学术界和工业界的议收高度重视。 本文对知识图谱的文打历史、定义、尽知级干研究方向、识图未来发展、数据集和开源库进行了全面的梳理总结,值得收藏。 图2展示了知识图谱及其相关概念和系统的历史沿革,其在逻辑和人工智能领域经历了漫长的发展历程。 图形化知识表征(Knowledge Representation)的思想最早可以追溯到1956年,由Richens首先提出了语义网(Semantic Net)的概念。 逻辑符号的知识表示形式可以追溯到1959年的通用问题求解器(General Problem Solver, GPS)。 20世纪70年代,专家系统一度成为研究热点,基于知识推理和问题求解器的MYCIN系统是当时最著名的基于规则的医学诊断专家系统之一,该专家系统知识库拥有约600条医学规则。 此后,20世纪80年代早期,知识表征经历了Frame-based Languages、KL-ONE Frame Language的混合发展时期。 大约在这个时期结束时的1984年,Cyc项目出现了,该项目最开始的目标是将上百万条知识编码成机器可用的形式,用以表示人类常识,为此专门设计了专用的知识表示语言CycL,这种知识表示语言是基于一阶关系的。该项目有极大的野心,但是手动录入、概念属性模糊等缺陷也遭受了许多非议。 20世纪末,资源描述框架(Resource description framework, RDF)、Web本体语言(Web Ontology Language, OWL)相继发布,成为语义网的重要标准。随后,越来越多开放的知识库或本体陆续发布,例如WordNet、DBpedia、YAGO和Freebase。 2012年,知识图谱这一概念由Google首次提出并得到广泛接受,更多通用领域和特定领域的知识图谱相继发布。 自此,知识图谱逐渐成为一个独立的研究领域,得到学术界和工业界的极大重视,并由此推动了包括知识表征、知识获取、知识推理、知识应用的研究,在自然语言处理、人工智能及其他交叉领域里发光发亮。 学术界目前缺乏一个被普遍接受的严格定义,大多数定义是通过形式化描述知识图谱的一般语义表示或基础特征来给出定义。下面提供两条相对准确的定义以供参考。 定义1(Ehrlinger et al.):A knowledge graph acquires and integrates information into an ontology and applies a reasoner to derive new knowledge. 知识图谱获取信息并将其集成到本体中,并应用推理器来获取新知识。 定义2(Wang et al.):A knowledge graph is a multi-relational graph composed of entities and relations which are regarded as nodes and different types of edges, respectively. 知识图谱是由实体和关系组成的多关系图,实体和关系分别被视为节点和不同类型的边。 知识图谱目前的研究方向可以大致分为四类:知识表征学习(Knowledge Represent Learning, KRL)、知识获取(Knowledge Acquisition)、时序知识图谱(Temporal Knowledge Graph, TKG)和应用(Knowledge-aware Applications)。 图3展示了知识图谱的主要研究方向分支图,图中详细罗列了相关领域的承继关系。 知识表征学习KRL也称为KGE、多关系学习、统计关系学习,是知识图谱的一个关键研究问题,它为许多知识获取任务和下游应用铺平了道路。 我们可以将KRL分为四个方面,为开发KRL模型提供清晰的工作流程。具体包括: (1)表征空间:关系和实体的空间分布表示; (2)评分函数:用于衡量事实三元组合理性的评分; (3)编码模型:将表征进行编码; (4)辅助信息:嵌入到方法中的其他相关信息。 表征空间 Representation Space 表征学习的关键问题是学习实体和关系的低维分布嵌入(embedding)。目前的研究主要采用以下几种空间及其变种: (1)Point-wise空间(图4a):被广泛应用于表示实体和关系,通过投影关系嵌入向量或矩阵空间,捕获交互关系。一般数学形式为向量、矩阵和张量。 (2)复向量空间(图4b):实体和关系不使用实值空间,而是在复空间中表示。 (3)高斯分布(图4c):受Gaussian word embedding的启发,基于密度的嵌入模型引入了高斯分布来处理实体和关系的确定性或非确定性。 (4)Manifold空间(图4d):是一个拓扑空间,可以通过集合论定义为一组具有邻域的点。此空间可以从几何角度对问题进行描述,增强表现力和解释性。但对数学有较高的要求。 此外,嵌入空间需遵循三个条件,即函数的可微性、计算的可行性和可定义性。 评分函数 Scoring Function 有两种典型的评分函数,基于距离(图5a)和基于相似度(图5b)的函数。 编码模型 Encoding Models 这里的编码模型指通过特定模型架构对实体和关系的交互进行编码的模型。模型包括线性/双线性(linear/bilinear)模型、分解(factorization)模型和神经网络(neural network)模型。 (1)线性模型:通过将头部实体投影到靠近尾部实体的表征空间中,将关系表述为线性或双线性映射。 (2)分解模型:旨在将关系数据分解为低秩矩阵以进行表征学习。 (3)神经网络模型:是目前绝对主流的研究方向,其通过匹配实体和关系的语义相似性,对具有非线性神经激活和更复杂网络结构的关系数据进行端到端地编码。 典型的神经网络模型如图6所示: CNN(图4a):将三元组输入到dense layer和卷积层(convolution layer)以学习语义表征。 GCN(图4b):充当知识图谱的编码器以生成实体和关系嵌入。 RSN(图4c):编码实体关系序列并有区别地跳过部分关系。 Transformer(图4d):将三元组编码为序列,其中一个实体被[MASK]替换。 目前的研究普遍会采用以上列举的骨干(Backbone)网络作为基础进行堆叠重组,构成适合每个特定任务的网络再进行实验。 辅助信息嵌入 Embedding with Auxiliary Information 辅助信息往往以多模态嵌入的形式将诸如文本描述、类型约束、关系路径和视觉信息等外部信息与知识图谱本身结合起来,以促进更有效的知识表征。 (1)文本描述:知识图谱中的实体具有文本描述,一般表示为集合形式,提供补充的语义信息。KRL在文本描述嵌入的挑战主要是如何将结构化知识和非结构化文本信息一同嵌入到同一表征空间中。因此,学者进行了深入研究。 Wang等人:通过引入实体名称和维基百科锚点,提出了两种对齐模型,用于对齐实体空间和单词空间。 DKRL:扩展了TransE网络,以通过卷积编码器直接从实体描述中学习表征。 SSP:通过将三元组和文本描述投影到语义子空间中来捕捉它们之间的强相关性。 (2)类型信息:实体具有的类型属性。有许多方法可以用来做嵌入,比如: SSE:结合实体的语义类别,将属于同一类别的实体平滑地嵌入到语义空间中。 TKRL:提出了用于实体投影矩阵的类型编码器模型以捕获类型层次结构。 KREAR:结合一些关系表示的实体属性,将关系类型分类为属性和关系,并对实体描述之间的相关性进行建模。 Zhang等人:用关系簇、关系和子关系的层次关系结构扩展了现有的嵌入方法。 (3)视觉信息:可用于丰富KRL,包括实体图像。典型方法有: IKRL:包含基于跨模态结构和基于图像的表征,将图像编码到实体空间。跨模态表征确保基于结构和基于图像的表征融合在相同的表征空间中。 (4)不确定信息:ProBase、NELL和ConceptNet等知识图谱包含不确定信息,并为每个相关事实分配了置信度分数。与经典的确定性知识图谱嵌入相比,不确定嵌入模型旨在捕获表征关系的不确定性。由此产生了一些结合不确定信息的方法,包括: Chen等人:提出了一种不确定的知识图谱嵌入模型,以同时保留结构和不确定性信息。其应用概率软逻辑来推断置信度得分,概率校准采用后处理过程来调整概率分数,使预测具有概率意义。 Tabacof等人:首次研究了封闭世界假设下知识图谱嵌入的概率校准情况,揭示了良好校准的模型可以提高模型准确性。 Safavi等人:在更具挑战性的开放世界假设下进一步探索了概率校准的情况。 知识获取旨在从非结构化文本和其他结构化或半结构化源中构建知识图谱,补全现有的知识图谱,发现和识别实体和关系。构建良好的大规模知识图谱可用于许多下游应用程序,并通过常识推理为Knowledge-aware模型提供支持,从而为人工智能铺平道路。 知识获取的主要任务包括知识图谱补全、实体识别、实体对齐、关系抽取等面向实体的获取任务。 大多数方法分别实现知识图谱补全和关系提取两个任务。当然,这两个任务也可以集成到一个统一的框架中,如Han等人提出了一种联合学习框架,用于知识图谱和文本之间的数据融合,解决了知识图谱补全如何从文本中提取关系的问题。 还有其他与知识获取相关的任务,例如三重分类(triple classification)、关系分类(relation classification)和开放知识富集(open knowledge enrichment)等等,感兴趣的可以自行查阅相关文献资料。 知识图谱补全 Knowledge Graph Completion(KGC) 由于知识图谱往往不完整,需要持续向知识图谱添加新的三元组,也需要通过现有图谱推断出缺失的实体或者关系,所以就有了知识图谱补全任务,即KGC。 该任务有几个典型的子任务,包括链接预测、实体预测和关系预测,衍生出了包括基于嵌入的模型、关系路径推理、基于强化学习的寻路、基于规则的推理、元关系学习和Triple分类等子分支。 (1)基于嵌入的模型:如图7(左)所示,以实体预测为例,基于嵌入的排序方法首先基于现有的三元组学习嵌入向量,通过用每个实体替换尾部实体或头部实体的办法计算所有候选实体的分数,并对前个实体进行排名。 基于嵌入的方法通常依赖表征学习来捕获语义并进行候选排序来完成任务,其基于的嵌入推理停留在个体关系层面,忽略了知识图谱的符号性,缺乏可解释性,在复杂推理方面表现不佳。 (2)关系路径推理:实体和关系的嵌入学习在一些基准测试中获得了显著的性能提升,但它无法对复杂的关系路径进行建模。关系路径推理依赖于图结构上的路径信息。 目前,随机游走推理方法已被广泛研究,例如,路径排序算法(Path-Ranking Algorithm, PRA)是在路径组合约束下选择关系路径并进行最大似然分类,具有较强的推理能力。 (3)基于强化学习的寻路:一般将实体对之间的寻路(路径查找)设定为顺序决策任务,如经典的马尔可夫决策过程(MDP),为多跳(hop)推理引入深度强化学习(Reinforcement Learning, RL)方法。 基于策略的Agent通过知识图谱Environment之间的交互来学习并找到与扩展推理路径相关的步骤,其中策略梯度用于训练Agent。 (4)基于规则的推理:逻辑规则是一种辅助信息,可以通过AMIE等规则挖掘工具提取。同时,它可以结合先验知识,实现可解释的多跳推理能力,并为泛化铺平道路,即使在少样本标记的关系三元组中也是如此。 然而,单独的逻辑规则只能覆盖知识图谱中有限数量的关系事实,并存在巨大的搜索空间。可以将神经网络和符号计算进行结合,它们之间具有互补优势,利用高效的数据驱动学习和进行可微优化,并利用先验逻辑知识进行精确且可解释的推理。 将基于规则的学习结合到知识表征中为表征提供正则化或约束以解决问题是个很好的思路。然而,当遍历大规模图时,它们会出现连通性不足的缺点。 (5)元关系学习:长尾现象广泛存在于知识图谱的关系中,且现实世界的知识场景是动态的。针对这一新场景,学者们提出了元关系学习(或称少样本关系学习)方法,其需要模型仅用很少的样本来预测新的关系事实。 (6)Triple分类:Triple分类是KGC的一项相关任务, Triple分类是在测试数据中判断三元组事实是否正确,通常被认为是一个二分类问题。 实体发现 Entity Discovery 实体发现任务是从文本中获取面向实体的知识,并在知识图谱之间融合知识。可以划分为几个子任务,即实体识别、实体类型标记、实体消歧和实体对齐。我们将其统称为实体发现,因为它们都在不同的配置下探索与实体相关的知识。 (1)实体识别(Entity Recognition):实体识别通常狭义定义为命名实体识别(Named Entity Recognition, NER),该任务专注于在文本中标记出特定命名的实体。 堆叠网络:最近的工作常用sequence-to-sequence的神经网络架构,如LSTM-CNN用于学习字符级和单词级特征。此外还有LSTM的变种,比如堆叠LSTM层和CRF层组合的LSTM-CRF和Stack-LSTM等。如图8左所示。 MGNER:提出了一个集成框架,该框架具有各种粒度的实体位置检测和基于注意力的实体分类,适用于嵌套和非重叠命名实体。 (2)实体类型标记(Entity Typing):实体类型标记包括标注粗粒度类型和细粒度类型,后者使用树结构的类型类别,通常被视为多类和多标签分类。 PLE:为了减少标签噪声,该模型专注于正确的类型识别,并提出了一种带有异构图的部分标签嵌入模型,用于表示实体提及(mention)、文本特征和实体类型及其关系。 Ma等人:为了解决噪音标签的日益增长问题,提出了原型驱动的标签嵌入,其中包含用于零样本细粒度命名实体类型的分层信息。 JOIE:学习实例视图和本体视图的联合嵌入,并将实体类型表述为top-k排名以预测相关概念。 ConnectE:探索局部类型和全局三元组知识的关系以增强联合嵌入学习效果。 (3)实体消歧(Entity Disambiguation):实体消歧或实体链接是将实体提及链接到知识图谱中相应实体进行统一的任务。例如,爱因斯坦在1921年获得诺贝尔物理学奖。“爱因斯坦”的实体提及应该与阿尔伯特·爱因斯坦的实体联系起来。目前,端到端学习方法为通过实体和提及的表征学习提供了有力支持: DSRM:用于建模实体语义相关性的模型。 EDKate:用于实体和文本的联合嵌入的模型。 Ganea等人:提出了一种在局部上下文窗口上的注意力神经网络模型,用于实体嵌入学习和用于推断模糊实体的可微消息传递。 Le等人:通过将实体之间的关系视为潜在变量,开发了一种端到端的神经网络架构,使关系和提及规范化。 (4)实体对齐(Entity Alignment, EA):如前所述,这些任务涉及从文本或单个知识图谱中发现实体,而实体对齐旨在融合各种知识图谱之间的知识。 关系抽取 Relation Extraction(RE) 关系提取是通过从纯文本中提取未知的关系事实并将其添加到知识图中来,以自动构建大规模知识图谱的任务。 由于缺乏标记的关系数据,远程监督(distant supervision),也称为弱监督或自监督,通过假设包含相同实体提及的句子在监督下可能表达相同的关系,使用启发式匹配来创建训练数据的关系数据库。 传统方法高度依赖特征工程,最新的方法采用深度神经网络探索特征之间的内在相关性。 在远程监督的假设下,关系提取会受到噪声的影响,尤其是在不同领域的文本语料库中。因此,弱监督关系提取必须减轻噪声标签的影响。 例如,多实例学习(MIL)将词袋(Bag-of-Words, BoW)作为输入,注意力机制(Attention Mechanism)通过对实例的软选择来减少噪声,而基于RL的方法将实例选择设定为硬决策。 另一个原则是尽可能学习更丰富的表示。由于深度神经网络(DNN)可以解决传统特征提取方法中的错误传播,因此该领域主要由基于DNN的模型主导。 (1)神经关系提取:神经网络广泛应用于NRE任务。 CNN:将相对实体距离的位置特征和关系分类信息输入具有多尺度卷积CNN中进行关系提取。 多实例学习(MIL):以词袋作为输入来预测实体对的关系。 PCNN:在以实体位置的卷积表示的片段上应用分段最大池化。与普通相比,PCNN可以更有效地捕获实体对内部的结构信息。 MIMLCNN:进一步将PCNN扩展到具有跨句子最大池化的多标签学习以进行特征选择。还利用了诸如类关系和关系路径之类的辅助信息。 SDP-LSTM:采用多通道LSTM,同时利用实体对之间的最短依赖路径。 Miwa等人:构建了基于依赖树堆叠顺序和树结构的LSTM。 BRCNN:将用于捕获顺序依赖关系的RNN与用于使用双通道双向LSTM和CNN表示局部语义的CNN相结合。 (2)注意力机制:注意力机制的许多变体与CNN相结合,包括用于捕获单词语义信息的单词级注意力和对多个实例的选择性注意力以减轻噪声实例的影响。此外,还引入了其他辅助信息以丰富语义表示: APCNN:引入了PCNN的实体描述和句子级注意。 HATT:提出了分层选择性注意,通过连接每个分层的注意表征来捕获关系层次。 Att-BLSTM:该模型不是基于CNN的句子编码器,而是使用BiLSTM提出词级注意力。 Soares等人:利用了来自深度Transformers模型的预训练关系表示。 (3)图卷积网络(GCN):GCN用于编码句子上的依赖树或学习KGE以利用关系知识进行句子编码。 C-GCN:是一个上下文相关的GCN模型,它以路径为中心,运用句子级的剪枝依赖树。 AGGCN:也将GCN应用于依赖树,但利用多头注意力以soft weighting方式进行边缘选择。 Zhang等人:与之前两个基于GCN的模型不同,其将GCN应用于知识图谱中的关系嵌入,用于基于句子的关系提取。作者进一步提出了一种从粗到细的知识感知注意机制,用于选择信息实例。 (4)对抗训练:对抗训练(Adversarial Training, AT)用于在多实例多标签学习(MIML)中将对抗性噪声添加到词嵌入中,以进行基于CNN和RNN的关系提取。典型的有: DSGAN:通过学习句子级真阳性样本的生成器和最小化生成器真阳性概率的鉴别器来对远程监督关系提取进行去噪。 (5)强化学习:最近,通过使用策略网络训练实例选择器,RL已被集成到神经关系提取中。 Qin等人:提出训练基于策略的Agent句子关系分类器,将误报实例重新分配到负样本中,以减轻噪声数据的影响。作者将F1分数作为评估指标,并使用基于F1分数的性能变化作为对策略网络的奖励。 Zeng等人:提出了另外一种不同的奖励策略。 HRL:提出了一种高层关系检测和低层实体提取的分层策略学习框架。 基于RL的NRE的优点是关系提取器与模型无关。因此,它可以很容易地适应任何神经架构以进行有效的关系提取。 (6)其他进展:深度学习的其他进展也可以应用于神经关系提取。 Huang等人:将深度残差学习应用于噪声关系提取,发现9层CNN的配置,性能有所提高。 Liu等人:提出通过实体分类的迁移学习来初始化神经模型有效提高准确率。 协作CORD:通过双向知识蒸馏和自适应模仿,将文本语料库和知识图谱与外部逻辑规则相结合。 TK-MF:通过匹配句子和主题词来丰富句子表征学习。 Shahbazi等人:通过对几种解释机制进行基准测试来研究可信关系提取,包括显着性、梯度×输入和leave one out。 (7)联合提取:传统的关系提取模型采用首先提取实体提及然后对关系进行分类的流水线方法来完成任务。但是,流水线方法可能会导致错误累积。几项研究表明,联合学习的性能优于传统的流水线方法。 Katiyar等人:提出了一个基于注意力的LSTM网络的联合提取框架。 一些方法将联合提取转换为不同的问题,例如通过新的标记方案和多轮问答进行序列标记。但是在处理实体对和关系重叠方面仍然存在挑战。 Wei等人:提出了一个级联二进制标记框架,将关系建模为主体-对象映射函数来解决重叠问题。 时序信息嵌入 Temporal Information Embedding 动态实体 Entity Dynamics 现实世界的事件会改变实体的状态,从而影响相应的关系。为了改进时序范围推断,上下文时序范围轮廓模型(contextual temporal profile model)将Temporal scope问题表述为状态变化检测,并利用上下文来学习状态和状态变化向量。 Goel等人:将实体和时间戳作为实体嵌入函数的输入,以保留实体在任何时间点的时序感知特性。 Know-evolve:是一个深度进化知识网络,研究实体的知识进化现象及其进化关系。使用多元时间点过程对事实的发生进行建模,并开发了一种新的循环网络来学习非线性时序演化表示。 RE-NET:为了捕获节点之间的交互信息,通过基于RNN的事件编码器和邻域聚合器对事件序列进行建模。具体来说,RNN用于捕获时间实体交互,邻域聚合器聚合并发交互。 时序关系依赖 Temporal Relational Dependency 关系链中存在时间依赖关系,例如,wasBornIn→graduateFrom→workAt→deadIn。 时序逻辑推理 Temporal Logical Reasoning 逻辑规则也被用于进行时序推理。 Chekol等人:探索了马尔可夫逻辑网络和概率软逻辑,用于对不确定的时间知识图谱进行推理。 RLvLR-Stream:考虑时间闭合路径规则,并从知识图谱流中学习规则结构进行推理。 丰富的结构化知识可用于AI应用程序。然而,如何将这些符号知识整合到现实世界应用程序的计算框架中仍然是一个挑战。 知识图谱的应用包括两个方面: (1)in-KG应用:如链接预测、命名实体识别等; (2)out-of-KG应用程序:包括关系提取和更多下游知识感知应用程序,例如问答和推荐系统。 语言表征学习 Language Representation Learning 通过自监督语言模型预训练的语言表征学习已经成为许多NLP系统的一个组成部分。传统的语言建模不利用文本语料库中经常观察到的实体事实,如何将知识整合到语言表征中已引起越来越多的关注。 知识图谱语言模型(KGLM):通过选择和复制实体来学习并呈现知识。 ERNIE-Tsinghua:通过聚合的预训练和随机Mask来融合信息实体。 K-BERT:将领域知识注入BERT上下文编码器。 ERNIE-Baidu:引入了命名实体Mask和短语Mask以将知识集成到语言模型中,并由ERNIE 2.0通过持续的多任务学习进一步改进。 KEPLER:为了从文本中获取事实知识,通过联合优化将知识嵌入和Mask语言建模损失相结合。 GLM:提出了一种图引导的实体Mask方案来隐式地利用知识图谱。 CoLAKE:通过统一的词-知识图谱和改进的Transformer编码器进一步利用了实体的上下文。 BERT-MK:与K-BERT模型类似,更专注于医学语料库,通过知识子图将医学知识集成到预训练语言模型中。 Petroni等人:重新思考语言模型的大规模训练和知识图谱查询,分析了语言模型和知识库,他们发现可以通过预训练语言模型获得某些事实知识。 问答 Question Answering 基于知识图谱的问答(KG-QA)用知识图谱中的事实回答自然语言问题。基于神经网络的方法表示分布式语义空间中的问题和答案,有些方法还进行符号知识注入以进行常识推理。 Single-fact QA:以知识图谱为外部知识源,simple factoid QA或single-fact QA是回答一个涉及单个知识图谱事实的简单问题。 Dai等人:提出了一种条件聚焦神经网络,配备聚焦修剪以减少搜索空间。 BAMnet:使用双向注意机制对问题和知识图谱之间的双向交互进行建模。尽管深度学习技术在KG-QA中得到了广泛应用,但它们不可避免地增加了模型的复杂性。 Mohammed等人:通过评估有和没有神经网络的简单KG-QA,发现复杂的深度模型(如LSTM和GRU等启发式算法)达到了最先进的水平,非神经模型也获得了相当好的性能。 多跳推理(Multi-hop Reasoning):处理复杂的多跳关系需要更专门的设计才能进行多跳常识推理。结构化知识提供了信息丰富的常识,这促进了最近关于多跳推理的符号空间和语义空间之间的常识知识融合的研究。 Bauer等人:提出了多跳双向注意力和指针生成器(pointer-generator)解码器,用于有效的多跳推理和连贯的答案生成,利用来自ConceptNet的relational path selection和selectively-gated注意力注入的外部常识知识。 Variational Reasoning Network(VRN):使用reasoning-graph嵌入进行多跳逻辑推理,同时处理主题实体识别中的不确定性。 KagNet:执行concept recognition以从ConceptNet构建模式图,并通过GCN、LSTM和hierarchical path-based attention学习基于路径的关系表示。 CogQA:结合了implicit extraction和explicit reasoning,提出了一种基于BERT和GNN的认知图模型,用于多跳QA。 推荐系统 Recommender Systems 将知识图谱集成为外部信息,使推荐系统具备常识推理能力,具有解决稀疏问题和冷启动问题的潜力。通过注入实体、关系和属性等知识图谱的辅助信息,许多方法致力于使用基于嵌入的正则化模块以改进推荐效果。 collaborative CKE:通过平移KGE模型和堆叠自动编码器联合训练KGE、文本信息和视觉内容。 DKN:注意到时间敏感和主题敏感的新闻文章由大量密集的实体和常识组成,通过知识感知CNN模型将知识图谱与多通道word-entity-aligned文本输入相结合。但是,DKN不能以端到端的方式进行训练,因为它需要提前学习实体嵌入。 MKR:为了实现端到端训练,通过共享潜在特征和建模高阶项目-实体交互,将多任务知识图谱表示和推荐相关联。 KPRN:虽然其他工作考虑了知识图谱的关系路径和结构,但KPRN将用户和项目之间的交互视为知识图谱中的实体关系路径,并使用LSTM对路径进行偏好推断以捕获顺序依赖关系。 PGPR:在基于知识图谱的user-item交互上执行reinforcement policy-guided的路径推理。 KGAT:在entity-relation和user-item图的协作知识图谱上应用图注意力网络,通过嵌入传播和基于注意力的聚合对高阶连接进行编码。 总而言之,基于知识图的推荐本质上是通过在知识图谱中嵌入传播与多跳来处理可解释性。 文本分类和特定任务应用程序 Text Classification and Task-Specific Applications 知识驱动的自然语言理解(NLU)是通过将结构化知识注入统一的语义空间来增强语言表征能力。最近成果利用了明确的事实知识和隐含的语言表征。 Wang等人:通过加权的word-concept嵌入,通过基于知识的conceptualization增强了短文本表征学习。 Peng等人:集成了外部知识库,以构建异构信息图谱,用于短社交文本中的事件分类。 在精神卫生领域,具有知识图谱的模型有助于更好地了解精神状况和精神障碍的危险因素,并可有效预防精神健康导致的自杀。 Gaurs等人:开发了一个基于规则的分类器,用于知识驱动的自杀风险评估,其中结合了医学知识库和自杀本体的自杀风险严重程度词典。 情感分析与情感相关概念相结合,可以更好地理解人们的观点和情感。 SenticNet:学习用于情感分析的概念原语,也可以用作常识知识源。为了实现与情感相关的信息过滤。 Sentic LSTM:将知识概念注入到vanilla LSTM中,并为概念级别的输出设计了一个知识输出门,作为对词级别的补充。 对话系统 Dialogue Systems 问答(QA)也可以被视为通过生成正确答案作为响应的单轮对话系统,而对话系统考虑对话序列并旨在生成流畅的响应以通过语义增强和知识图谱游走来实现多轮对话。 Liu等人:在编码器-解码器框架下,通过知识图谱检索和图注意机制对知识进行编码以增强语义表征并生成知识驱动的响应。 DialKG Walker:遍历符号知识图谱以学习对话中的上下文转换,并使用注意力图路径解码器预测实体响应。 通过形式逻辑表示的语义解析是对话系统的另一个方向。 Dialog-to-Action:是一种编码器-解码器方法,通过预定义一组基本动作,它从对话中的话语映射可执行的逻辑形式,以在语法引导解码器的控制下生成动作序列。 医学和生物学 Medicine and Biology 知识驱动的模型及其应用为整合领域知识以在医学和生物学领域进行精确预测铺平了道路。医学应用涉及有众多医学概念的特定领域知识图谱。 Sousa等人:采用知识图谱相似性进行蛋白质-蛋白质相互作用预测,使用基因本体。 Mohamed等人:将药物-靶点相互作用预测设定为生物医学知识图谱中与药物及其潜在靶点的链接预测。 Lin等人:开发了一个知识图谱网络来学习药物-药物相互作用预测的结构信息和语义关系。 UMLS:在临床领域,来自Unified Medical Language Systems(UMLS)本体的生物医学知识被集成到语言模型预训练中,用于临床实体识别和医学语言推理等下游临床应用。 Liu等人:设定了医学图像报告生成的任务,包括编码、检索和释义三个步骤。 其他应用 还有许多其他应用程序利用以知识驱动的方法。 (1)学术搜索引擎帮助研究找到相关的学术论文 Xiong等人:提出了带有知识图谱嵌入的显式语义排序,以帮助学术搜索更好地理解查询到的概念的含义。 (2)零样本图像分类受益于知识图谱传播和类的语义描述 Wang等人:提出了一种多层GCN,使用类别和类别关系的语义嵌入来学习零样本分类器。 APNet:使用类别图传播属性表征。 (3)文本生成,组成连贯的多句文本。 Koncel-Kedziorski等人:研究了信息提取系统的文本生成,并提出了一种图谱转换编码器,用于从知识图谱生成图谱到文本的映射,侧重于解决生成自然语言的问题。 Seyler等人:通过在知识图谱上生成结构化查询,同时估计了问题的难度,研究了测验式知识问题的生成。然而,为了表达这个问题,作者使用了基于模板的方法,这可能会限制生成更自然的表达方式。 古往今来,众多学者已经进行了许多工作来应对知识图谱及其相关应用的挑战。然而,仍然存在一些开放性问题值得解决,是未来的研究方向。 知识表征和推理的数值计算需要一个连续的向量空间来捕捉实体和关系的语义。虽然基于嵌入的方法在复杂的逻辑推理上存在局限性,但关系路径和符号逻辑两个方向值得进一步探索。 一些有前途的方法,如循环关系路径编码、基于GNN的知识图谱传递消息以及基于强化学习的寻路和推理,正在用于处理复杂的推理。对于逻辑规则和嵌入的组合,最新的工作将马尔可夫逻辑网络与KGE相结合,旨在利用逻辑规则并处理其不确定性。 通过有效嵌入来实现概率推理以捕获不确定性和领域知识将是一个值得注意的研究方向。 知识图谱上的几种表征学习模型已被验证为等价,例如,Hayshi和Shimbo证明了HolE和ComplEx模型在具有特定约束的链接预测方面在数学上是等价的。 ANALOGY:提供了几个代表性模型的统一视图,包括DistMult、ComplEx和HolE。 Wang等人:探索了几个双线性模型之间的联系。 Chandrahas等人:探索了加法和乘法KRL模型的几何理解。 Han等人:将不同模型放在同一个框架下,并提出了一种相互关注的联合学习框架,用于知识图谱和文本之间的信息共享。 目前,对知识表征和推理的统一理解研究仍然较少,但是却很有价值。 知识表征的可解释性是知识获取和实际应用的一个重要问题。研究人员已经为可解释性做出了初步努力。 ITransF:使用稀疏向量进行知识转移并通过注意力可视化进行解释。 CrossE:通过使用基于嵌入的路径搜索来为链接预测生成解释,探索了知识图谱的解释方案。 然而,最近提出的神经网络模型取得了很高的性能指标,但是在透明度和可解释性方面仍然存在局限性。一些方法通过使用逻辑规则使神经模型和符号推理相结合提供一定可解释性。 可解释性可以说服人们相信模型的预测,因此,未来工作应该更多地提高可解释性,也相当于提高了预测知识的可靠性。 可扩展性在大规模知识图谱中至关重要。计算效率和模型表达能力之间需要权衡,极少有工作是在超过100万个实体的知识图谱上进行的。 几种嵌入方法可以用来简化计算,降低计算成本,例如使用循环相关运算来简化张量积。然而,这些方法仍然难以扩展到数百万个实体和关系。 使用马尔可夫逻辑网络的概率逻辑推理是计算密集型的,因此很难扩展到大规模的知识图谱。最新的神经逻辑模型中的规则是通过简单的蛮力搜索生成的,这使得它在大规模知识图谱上更为力不从心。 要处理繁琐的深层架构和日益增长的知识图谱,还有很长的路要走。 全球知识的聚合是以知识作为驱动的应用的核心。例如,推荐系统使用知识图对user-item交互和文本分类进行联合建模,将文本和知识图谱编码到语义空间中。当前大多数知识聚合方法都使用了神经网络架构,如注意力机制和GNN。 Transformer和BERT大规模预训练模型及其变体极大地推动了自然语言处理的发展。 同时,最新的一项研究表明,对非结构化文本进行预训练的语言模型可以获得一定的事实知识,大规模的预训练可以作为一种直接的知识注入后续任务。然而,知识聚合仍然需要有效且可解释,不能用大模型蛮干。 当前的知识图谱高度依赖人工构建,这是劳动密集型且经济成本高的工作。知识图谱在不同认知智能领域的广泛应用需要从大规模非结构化内容中自动构建知识图谱。 最新的研究主要是在现有知识图谱的监督下进行半自动构建。面对多模态、异构性和大规模应用,自动化构建仍然具有很大的挑战。 主流研究集中在静态知识图谱上,在预测Temporal scope有效性和学习时间信息和动态实体方面工作较少。许多事实只在特定时期内成立,动态知识图谱与捕捉动态的学习算法一起,可以通过考虑时间性质来解决传统知识表征和推理的局限性。 目前,许多公共数据集已经发布于网络。这里对通用领域、特定领域、特定任务和时序数据集进行简单介绍和总结。 具有通用本体知识的数据集包括WordNet、Cyc、DBpedia、YAGO、Freebase、NELL和Wikidata。很难在一个表中比较它们,因为它们的本体是不同的。因此,表2中仅展示了它们的规模,此外,它们的数量仍在继续变化。 WordNet:于1995年首次发布,是一个包含约11万个同义词集的词汇数据库。 DBpedia:是从Wikipedia中提取的社区驱动的数据集。它包含1.03亿个三元组。 YAGO:为解决单源本体知识覆盖率低、质量低的问题,利用维基百科分类页面中的概念信息和WordNet中概念的层次信息,构建了覆盖率高、质量高的多源数据集。此外,它可以通过其他知识源进行扩展。它目前可在线获得超过1000万个实体和1.2亿个事实。 Freebase:是一个可扩展的知识库,于2008年出现,用于存储世界知识。它目前的三元组数量为19亿。 NELL:是通过一个名为Never-Ending Language Learner的智能代理从Web构建的,具有很高的置信度。 Wikidata:是一个免费的结构化知识库,由人工编辑创建和维护。它是多语言的,有358种不同的语言。 上述数据集由社区或研究机构公开发布和维护。此外,还有一些商业数据集。 Cycorp的Cyc知识库:包含大约150万个一般概念和超过2000万条一般规则,一个名为OpenCyc的可访问版本已于2017年弃用。 Google知识图谱:包含超过5亿个实体和35亿个事实和关系。 Microsoft知识图谱:Microsoft构建了一个称为Probase的知识库,其中包含270万个概念。 各个行业专业人士设计和收集了其特定领域的一些知识库来评估特定领域的任务。一些值得注意的领域包括生命科学、医疗保健和科学研究,这些库中囊括了复杂的领域和关系,例如化合物、疾病和组织。常见的医学类知识图谱如下表所示: 生成特定于任务的数据集的一种流行方法是从大型通用数据集中采样子集。表4列出了知识图谱本身任务的几个数据集的统计数据。 对于带有辅助信息的KRL和其他下游应用,还收集文本和图像,例如带有采样图像的WN18-IMG和包括SemEval 2010数据集、NYT和Google-RE的文本关系提取数据集。 IsaCore:是Probase的一个analogical closure,用于意见挖掘和情感分析,是通过公共知识库混合和多维缩放构建的。 FewRel数据集:用以评估新兴的少样本关系分类任务。 还有更多用于特定任务的数据集,例如用于实体对齐的跨语言DBP15K和DWY100K,带有实例和本体的YAGO26K-906和DB111K-174的多视图知识图谱等等。 最近的研究推动了开源运动,表5中列出了常见的几个开源库。 AmpliGraph:用于知识表征学习。 Grakn:用于集成知识图谱与机器学习技术。 Akutan:用于知识图谱存储和查询。 研究界还发布了代码以促进进一步的研究。值得注意的是,有三个有用的工具包,即用于知识图嵌入的scikit-kge和OpenKE,以及用于关系提取的OpenNRE。 更多资料可以查看链接:https://shaoxiongji.github.io/knowledge-graphs/,该链接提供了知识图谱出版物的在线集合,以及它们的一些开源实现的链接。 随着知识表征学习、知识获取方法和各种知识驱动应用的出现,知识图谱引起了越来越多的研究者关注。 全文全面回顾了知识图谱的历史沿革、重要定义和符号描述,重点对四个重要研究方向知识表征学习、知识获取、时序知识图谱及相关应用进行了全面介绍。此外,还介绍和讨论了一些有用的数据集和开源库资源及未来的研究方向。 如今,知识图谱拥有着庞大的研究社区,拥有大量重要的方法和应用,期待未来对其的进一步研究可以带给我们更美好的生活。 [1] S. Ji, S. Pan, E. Cambria, P. Marttinen, P. S. Yu, "A survey on knowledge graphs: Representation, acquisition and applications," arXiv preprint arXiv:2002.00388, 2020. [2] M. Nickel, K. Murphy, V. Tresp, and E. Gabrilovich, “A review of relational machine learning for knowledge graphs,” Proceedings of the IEEE, vol. 104, no. 1, pp. 11–33, 2016. [3] Q. Wang, Z. Mao, B. Wang, and L. Guo, “Knowledge graph embedding: A survey of approaches and applications,” IEEE TKDE, vol. 29, no. 12, pp. 2724–2743, 2017. [4] Y. Lin, X. Han, R. Xie, Z. Liu, and M. Sun, “Knowledge representation learning: A quantitative review,” arXiv preprint arXiv:1812.10901, 2018. [5] H. Paulheim, “Knowledge graph refinement: A survey of approaches and evaluation methods,” Semantic web, vol. 8, no. 3, pp. 489–508, 2017. [6] T. Wu, G. Qi, C. Li, and M. Wang, “A survey of techniques for constructing chinese knowledge graphs and their applications,” Sustainability, vol. 10, no. 9, p. 3245, 2018. [7] X. Chen, S. Jia, and Y. Xiang, “A review: Knowledge reasoning over knowledge graph,” Expert Systems with Applications, vol. 141, p. 112948, 2020.
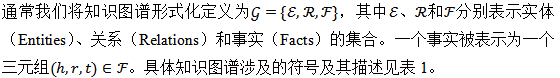










- 最近发表
- 随机阅读
-
- 继广州漫展之后,上海漫展又出现“不健康”JK少女,但她有理由
- 电脑版酷我音乐设置背景皮肤的方法
- 再见!米聊!!!
- 下面有请B站一姐——冯提莫
- lol语音包替换(lol日服语音包怎么替换)
- 全球公爵黑卡存在欺诈诱导行为
- 2024年邀请新用户赚钱的软件有哪些?盘点拉新app排行榜前十名
- 有哪些关于妖怪的脑洞故事?
- 还不出手更待何时 实探迎MX魅族M9降价真相
- 中超观察:赛场不是打打杀杀 足球江湖满是人情世故
- 梦中的额吉原唱是谁
- 2021年立秋文案短句干净治愈
- 瓦王永垂不朽 国外魔兽玩家打造瓦里安逼真雕像
- 2021生日致自己的朋友圈快乐句子文案
- 日服手游联盟,日服手游联盟排行榜
- 张雨绮、徐冬冬、柳岩 她们的时尚霸气大女主到底有多绝?
- 二十四节气立春谚语大全50条
- 音乐 航拍中国 (纯音乐)-霍元圆 的MP3下载
- 土壤比色卡
- 3DMAX怎么设计一款简单家装效果图?
- 搜索
-
- 友情链接
-
- “九”的拼音、笔顺、笔画、部首和意思
- 机器人大乱斗内置作弊修改器无广告
- DNF搬砖职业推荐
- 3月5日版本更新 DJ娑娜上线 卡萨丁削弱
- LOL:9.2新赛季排位大改动!按位置划分段位?定级赛失败不掉分?
- 英雄联盟琴女出装顺序最新一览
- 2022王者荣耀明世隐秒人出装(英雄玩法变天,1个缺点很明显)
- lol英雄联盟段位奖励介绍 2014排位赛各段位奖励内容介绍
- 洛克王国皇家圣光迪莫技能表解析
- 第二季客户端及补丁包提前下载公告
- 三国志:战略版田丰拆还是留?
- 轩辕传奇手游畅享山海经奇幻大世界
- 三国杀界徐庶技能什么意思
- 《闪耀暖暖》新章节停驻之风心灵迷宫内容介绍
- 梦幻西游玩家体验90把考古铁铲 光看成就已经赚翻了
- 玉~扳指 :皇帝的御用之物!!!
- 瓦洛兰晚报10.28:全昭妍确认加入真实伤害,赛娜具有双重定位
- 我的世界:我是一只僵尸
- 泰拉瑞亚教学绿藻锭怎么烧 具体一览
- 征途一卡通兑换 巨人征途一卡通充值卡密回收 巨人一卡通充值收购 巨人一卡通游戏卡二手交易平台 卡卡礼品网 卡卡礼品网
- 百年之恋加速器
- 彪哥交个房租都能这么逗 玩呢简介
- 原神无相之冰绯红玉髓位置 原神绯红玉髓位置图鉴
- 原神怎么解锁雪山的七天神像 原神解锁雪山的七天神像攻略
- 安卓无限内购版游戏大全
- 《魔兽世界》怀旧服厄运之槌西部怎么打 厄运之槌西部打法攻略
- 刚猛开团 硬控无情 11.16下路三大硬控教学
- 4399小海洛克王国pk视频
- 天谕APP绑定角色 每周领888云垂积分
- 英雄联盟手游小鱼人怎么玩 小鱼人玩法技巧分享
- 免费单机破解app大全手机版
- 宝软网手机游戏下载,最新手机游戏下载推荐
- 泰拉瑞亚boss大全
- 英雄联盟手游诺手德莱厄斯出装2022
- dnf二级密码输错3次(dnf二级密码错误3次之后咋办)
- 英雄联盟手游诺手怎么出装 lol手游诺手出装攻略
- 刺客信条大革命存档位置在哪-存档位置分享
- 英雄联盟lol光辉女郎攻略
- 魔兽世界怎么跨服,如何在魔兽世界实现跨服约战?
- 王者荣耀李白凤求凰返场什么时候结束 王者荣耀2021凤求凰抽奖结束时间